前言
为解决LLM知识库的局限性、幻觉问题和数据安全性的问题,RAG检索增强生成(Retrieval Augmented Generation)应运而生,已经成为这些年最火热的LLM应用方案。而本人在使用RagFlow构建本地知识库时,发现其自带的DeepDoc解析PDF的效果不是很理想,为了解决这个问题找了MinerU这款PDF神器来替代DeepDoc解析PDF。本文主要整理了本地部署MinerU2.0的步骤,包含cpu和gpu两种模式(文章当前最新MinerU版本为mineru-2.0.6-released)。
一、MinerU介绍
MinerU是一款由上海人工智能实验室的大模型数据基础团队(OpenDataLab)开发的开源数据提取工具,专门用于高效地从复杂的 PDF 文档、网页和电子书中提取内容。想了解MinerU提取数据的原理可参考官方PPT文档
官方在线体验地址:
1. 拉取代码安装依赖
1 | # 拉取项目源码 |
2. mineru命令下载模型
1 | # 命令下载模型 |
下载的模型大概4.22G,默认下载到了C:\Users\username.cache\modelscope目录,后续使用命令解析PDF就不需要重复下载模型了
3. gpu模型安装coda和替换coda相关包(cpu模式可跳过该步骤)
| 解析后端 | pipeline | vlm-transformers | vlm-sgslang |
| 操作系统 | windows/linux/mac | windows/linux | windows(wsl2)/linux |
| 内存要求 | 最低16G以上,推荐32G以上 | ||
| 磁盘空间要求 | 20G以上,推荐使用SSD | ||
| python版本 | 3.10-3.13 | ||
| CPU推理支持 | ✅ | ❌ | ❌ |
| GPU要求 | Turing及以后架构,6G显存以上或Apple Silicon | Ampere及以后架构,8G显存以上 | Ampere及以后架构,24G显存及以上 |
参考上面官方推荐系统配置,本人电脑满足最低配置要求,coda安装过程
3.1 安装nvidia coda
CUDA官网下载地址我这里选择 Windows 11 64-bit,推荐 exe (network)或 exe (local)版本。
根据自己的window系统版本下载对应的安装包,双击安装包选择默认安装选项即可,安装后最后重启下系统。
3.2 替换torch相关依赖为coda版本
1 | # 激活虚拟环境 |
4. 使用mineru命令解析PDF
详细命令行使用参考MinerU官方命令行使用方式
最简单的命令行调用方式如下:
1 | # 解析文件命令 注意结尾加上 --source local 使用本地已经下载的模型 |
<input_path>:本地 PDF 文件或目录(支持 pdf/png/jpg/jpeg)<output_path>:输出目录
5. cpu和gpu模式简单对比
这里我用了一个105页的PDF文档通过不同的模型来对比:
5.1 耗时对比
cpu模式:
可以看出cpu模式解析这个PDF的总耗时为15分8秒
gpu模式:
可以看出gpu模式解析这个PDF的总耗时为2分3秒
耗时差距7-8倍左右,可以看出gpu的加速还是比较明显的
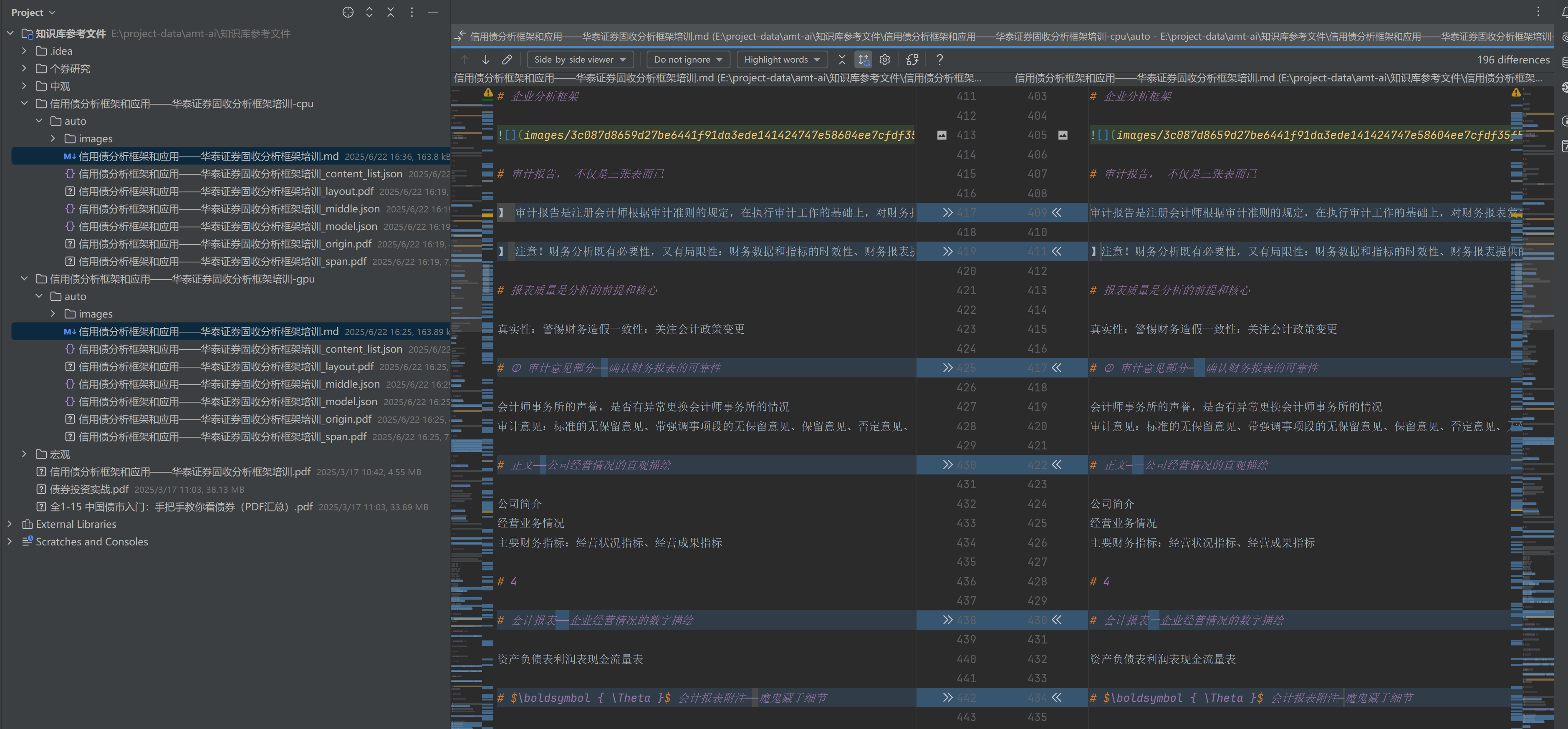
5.2 效果对比
通过IDEA对比解析后的markdown文件内容,发现其中的差异基本就是标点符号上细微的解析差异,两种模式的解析效果都不错差距不是很大。
参考文章
1.一文搞懂大模型RAG应用(附实践案例)
2.MinerU vs DeepDoc:集成方案+图片显示优化

- 本文作者: yinshuang
- 本文链接: https://yinshuang007.github.io/2025/06/22/PDF解析神器MinerU本地部署/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!